If you’ve ever copied a link that suddenly stopped working, or wondered why a perfectly typed search query returned zero results — you might have run into a URL encoder spellmistake without even knowing it. This is one of those problems that looks tiny on the surface but can quietly wreck your website’s performance, break your analytics, and confuse search engine crawlers in ways that take weeks to diagnose.
In this guide, we’re going to break down exactly what the url encoder spellmistake phenomenon means, why it keeps happening even to experienced developers, how it affects your SEO, and — most importantly — how you can prevent it for good.

What Is URL Encoding and Why Does It Even Matter?
URL encoding, technically known as percent-encoding, is the process of converting characters that aren’t safe for internet transmission into a standardized %XX format. Browsers and servers only support a limited set of ASCII characters in web addresses. Everything else — spaces, symbols, non-Latin scripts, emojis — needs to be transformed before it travels across the web.
Here’s what that looks like in practice:
- A space becomes %20
- The @ symbol becomes %40
- A forward slash / becomes %2F
- The ampersand & becomes %26
Without this conversion, a URL containing a space or a special character would simply break. Web servers wouldn’t know how to interpret it, browsers would throw errors, and users would land on dead pages. URL encoding is not optional — it’s a core requirement of how the internet functions at its most basic level.
This process is particularly critical in query parameters, API endpoints, form submissions, and any dynamic web pages that construct URLs from user input.
What Does “SpellMistake” Actually Mean in This Context?
Here’s where people get genuinely confused. The phrase url encoder spellmistake doesn’t mean your URL encoder is checking your grammar. It refers to two separate — and frequently mixed up — categories of errors:
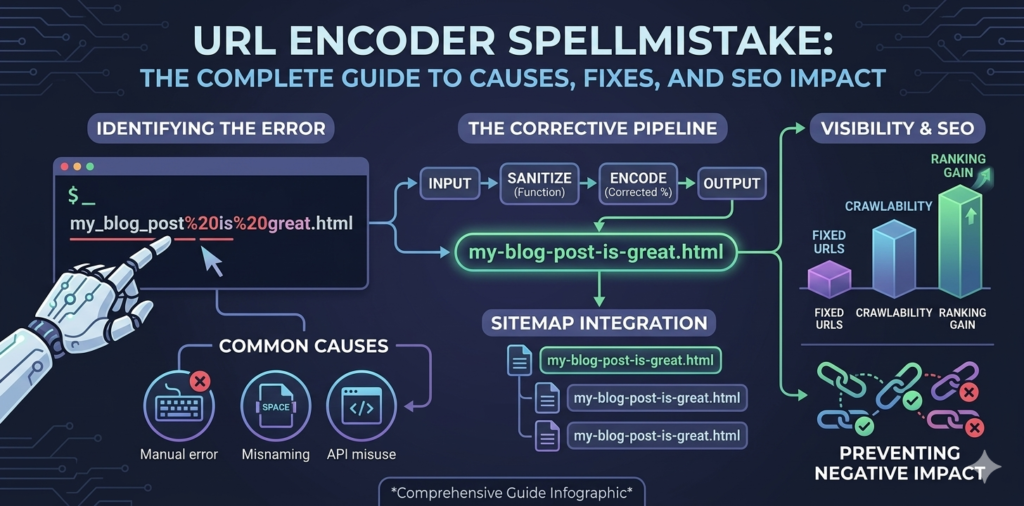
First, there’s a literal spelling error in the text before encoding happens. Someone types “contcat” instead of “contact,” and the encoder faithfully converts that mistake into a perfectly formatted, perfectly broken encoded string.
Second, there are encoding-specific mistakes — wrong hex values, double encoding, missed percent signs — that have nothing to do with English spelling but are “mistakes in how encoding was performed.”
The confusion between these two categories is exactly what makes URL encoder spellmistake such a tricky phrase. And it’s why so many people assume encoders are smarter than they are. A URL encoder preserves mistakes — it does not correct them. Whatever goes in, comes out encoded, errors and all.
The Most Common URL Encoder SpellMistake Types
Understanding the specific types of encoding errors helps you spot them faster and fix them without guesswork.
Double Encoding — The Silent Killer
Double encoding is probably the most damaging and hardest-to-spot mistake. It happens when an already-encoded string gets encoded a second time.
Here’s how the math breaks down:
- Original text: hello world
- First encoding: hello%20world ✓
- Second (accidental) encoding: hello%2520world ✗
What happened? The % sign itself gets encoded as %25 during the second pass, turning %20 into %2520. The URL now points somewhere completely different. This causes broken redirects, 404 errors, and in some CMS environments, duplicate content problems that confuse search engines for months.
Wrong Hex Values
This one happens during manual encoding. Someone replaces a letter with a number, or vice versa, while typing out a %XX sequence. For example, writing %2O instead of %20 — using the letter O instead of the number zero. The difference looks almost invisible on screen but completely breaks the URL.
Mixing + and %20 Incorrectly
This is a subtle but important encoding rule that even experienced developers get wrong. Spaces can be represented as either %20 or + depending on the context — and using the wrong one breaks things.
| Context | Correct Space Encoding |
| URL path segment (/search/hello world) | %20 only |
| HTML form POST body (application/x-www-form-urlencoded) | + is valid |
| Modern query strings | %20 preferred |
| Fragment identifiers (#section name) | %20 only |
The + sign is only valid in form-encoded POST bodies. Everywhere else, %20 is the correct representation. Mixing these up causes parameter parsing failures and incorrect analytics tracking, especially when UTM parameters are involved in campaign tracking.
Also Read Jynxzi Real Name Revealed
Also Read Dan Katz Wife: The Complete Story of Stephanie Maloney Katz
Also Read Nikki Hakuta: The Untold Story of Ali Wong’s Daughter, Her Heritage, and a Family Built on Privacy
Encoding Reserved Characters Incorrectly
Reserved characters like ?, &, #, /, and = have specific structural roles in a URL. Whether you encode them or leave them raw depends entirely on their function within the URL structure.
If & is separating two query parameters, it must stay raw. If it appears inside a parameter value, it must be encoded as %26. Getting this wrong disrupts communication between browsers and servers at a fundamental level.
Copy-Paste Formatting Errors
This one catches people off guard. Text copied from emails, PDFs, or Word documents sometimes contains hidden Unicode characters — “smart quotes,” non-breaking spaces, or invisible formatting characters — that look identical to standard text on screen but produce malformed encoded strings when processed. This is especially common in marketing teams building URLs manually for campaigns.
How UTF-8 Pre-Processing Works — The Step Competitors Miss
This is the part that almost nobody explains properly, and it causes real problems particularly for websites targeting international audiences.
Before percent-encoding can be applied to non-ASCII characters — things like Hindi script (हिंदी), Arabic letters (عربي), accented French characters (é, ç), or even emoji (🎉) — those characters must first be converted into their UTF-8 byte sequences. Only then does percent-encoding get applied to each individual byte.
Here’s a concrete example using the emoji 🎉:
- The emoji 🎉 has a Unicode code point of U+1F389
- Its UTF-8 byte sequence is: F0 9F 8E 89
- After percent-encoding each byte: %F0%9F%8E%89
So the correct encoded form of 🎉 in a URL is %F0%9F%8E%89, not some simplified shortcut.
If you skip the UTF-8 conversion step and try to encode non-ASCII characters directly, you get garbled URLs, redirect failures, and serious international SEO problems — particularly broken hreflang tags on multilingual sites. Search engines won’t be able to correctly associate your English page with its Arabic or Hindi equivalent, tanking your international search visibility.
For developers, the practical rule is: always use standard library functions that handle UTF-8 conversion automatically. In JavaScript, encodeURIComponent() handles this correctly. In Python, urllib.parse.quote() does the same. In PHP, urlencode() takes care of it. Don’t try to manually replicate what these functions do — that’s how encoding mistakes creep in.
Also Read New Software Name mozillod5.2f5: Complete Guide to Features, Performance & Why It Matters
Also Read PedroVazPaulo Business Consultant: The Complete 2026 Guide to Strategy, Growth & Real Results
How URL Encoder SpellMistake Impacts SEO
A single malformed URL might seem like a minor inconvenience. But at scale — across hundreds of pages, campaign links, and API calls — the cumulative damage is significant.
Crawlability takes the first hit. Search engine bots follow URLs to discover and index content. When they encounter invalid percent-encoding, they may fail to crawl the page at all, or crawl a broken variant that returns an error.
Duplicate content is another major risk. The same page might be accessible at example.com/search?q=hello%20world and example.com/search?q=hello%2520world due to double encoding. Google sees these as two different URLs showing identical content — a canonical URL nightmare that forces you to manually intervene in Google Search Console.
Crawl budget waste is the third dimension. For larger websites, bots have a finite number of pages they’ll crawl during each visit. If malformed URLs generated by encoding errors create dozens of invalid URL variants, bots spend their budget on garbage instead of your actual content.
And finally, UTM parameter corruption silently breaks your marketing attribution. If the encoded tracking links in your email campaign are malformed, your analytics platform can’t parse them correctly. Traffic gets misattributed, conversion data becomes unreliable, and your marketing reports are effectively fiction.
How to Find and Fix Encoding Errors on Your Site
Finding these problems early is far easier than untangling them after the fact.
Step 1 — Run an SEO Crawl Tools like Screaming Frog or Sitebulb scan your entire site and flag URLs with malformed encoding, unusual %25 patterns, and redirect chain issues. This is your fastest first pass.
Step 2 — Check Google Search Console Look for crawl anomalies, 404 spikes, and URL parameter issues. If you see a sudden spike in errors after a site update or campaign launch, encoding is often the culprit.
Step 3 — Inspect Server Logs Your server logs show you exactly which URLs are being requested. Watch for 400 Bad Request errors and malformed query strings — these are strong indicators of a url encoder spellmistake in the wild.
Step 4 — Decode Suspicious URLs If a URL looks strange, paste it into a URL decoder and see what the original string was. If %2520 appears where you expected %20, you’ve found double encoding.
Step 5 — Re-encode Using Trusted Functions Fix the source. Whether the error comes from a CMS plugin, JavaScript snippet, or a manually built marketing link — go back to the origin and replace manual encoding with a standard function like encodeURIComponent() or urlencode().
Step 6 — Update Canonicals and Test Redirects After fixing encoding at the source, update your canonical URLs and verify that all redirects resolve correctly. Skipping this step risks leaving duplicate indexed pages even after the underlying error is fixed.
Best Practices to Prevent URL Encoding Mistakes
Once you understand the problem, prevention becomes mostly about building good habits.
Never encode URLs by hand. Manual encoding is the single biggest source of hex value errors and double encoding mistakes. Standard library functions handle edge cases automatically — trust them.
Always spell-check content before it enters a URL. Since encoding preserves mistakes rather than fixing them, any typo in the source text becomes a permanent fixture of the encoded string. A spell checker before encoding is much cheaper than a debugging session after.
Validate URLs in your CI/CD pipeline. Automated checks during deployment catch encoding issues before they ever reach production. This is especially important for e-commerce platforms and content-heavy sites where URLs are generated programmatically.
Use consistent encoding conventions across your entire stack. If your frontend uses %20 for spaces, your backend and redirects should match. Inconsistency between systems is a major cause of parameter explosion — where invalid encoding creates infinite URL variants that bleed crawl budget.
Monitor your analytics for traffic drops or unusual bounce rate spikes after deployments or campaign launches. These are often the first visible symptoms of a url encoder spellmistake that’s been silently doing damage.
Conclusion
The url encoder spellmistake isn’t just a quirky technical phrase — it represents a category of silent, easy-to-miss errors that can affect everything from user experience to search rankings. URL encoding preserves mistakes rather than correcting them, which means that a typo, a double-encoded string, or a skipped UTF-8 conversion step gets locked into your URL exactly as it was entered.
Understanding the difference between a literal spelling error and an encoding syntax error helps you diagnose problems faster. Using standard encoding functions, validating URLs before publishing, and building encoding checks into your deployment workflow are the habits that keep these issues from compounding over time.
Precision in URL construction isn’t pedantry — it’s the foundation of a reliable, crawlable, and user-friendly web presence.
FAQs
Does a URL encoder fix spelling mistakes automatically? No, it doesn’t. A URL encoder only converts characters into a safe %XX format. Any spelling error present in the original text remains unchanged after encoding. Always spell-check content before applying URL encoding.
What is double encoding and why is it a problem? Double encoding happens when an already-encoded URL is encoded again, turning %20 into %2520. This produces broken links, 404 errors, and duplicate content issues that can seriously harm crawlability and SEO performance.
Can URL encoding errors affect my Google rankings? Yes, they can. Encoding errors cause crawl failures, duplicate URLs, broken redirects, and wasted crawl budget — all of which negatively impact how search engines discover and index your content, potentially lowering your visibility.
Which encoding function should I use to avoid mistakes? Use encodeURIComponent() in JavaScript, urllib.parse.quote() in Python, or urlencode() in PHP. These standard library functions handle UTF-8 conversion and edge cases automatically, eliminating the most common sources of manual encoding errors.

